// ==UserScript==
// @name Replit Chat Completion Ping (Stop/Working FSM + Airy Harp Chime)
// @namespace nicholas.tools
// @version 1.4.0
// @description Chimes when Replit chat finishes. Detects streaming via Stop or "Working..". Uses Sound #4 (Airy harp up-gliss). Rich console logs + control panel (window.ReplitPing).
// @match https://replit.com/*
// @grant none
// @run-at document-idle
// ==/UserScript==
(() => {
"use strict";
/* =========================
* Config
* ========================= */
let DEBUG = true; // high-level logs (state changes, detections)
let TRACE_SCAN = false; // very chatty: log detector scans (toggle at runtime)
const STABILITY_MS_DEFAULT = 200; // require this much time of "no Stop & no Working" before DONE
let STABILITY_MS = STABILITY_MS_DEFAULT;
const POLL_MS = 250;
// Matchers (case-insensitive)
const STOP_TEXTS = ["stop"]; // exact match (normalized)
const WORKING_TOKENS = ["working"]; // starts-with; allows Working., Working.., Working…
/* =========================
* Pretty Console Logging
* ========================= */
const tag = (lvl) => [
"%cREPLIT-PING%c " + lvl + "%c",
"background:#121212;color:#00e5ff;padding:1px 4px;border-radius:3px",
"color:#999",
"color:inherit"
];
const cI = (...a) => DEBUG && console.log(...tag("ℹ️"), ...a);
const cS = (...a) => DEBUG && console.log(...tag("✅"), ...a);
const cW = (...a) => DEBUG && console.log(...tag("⚠️"), ...a);
const cE = (...a) => DEBUG && console.log(...tag("⛔"), ...a);
const cT = (...a) => (DEBUG && TRACE_SCAN) && console.log(...tag("🔎"), ...a);
const nowStr = () => new Date().toLocaleTimeString();
/* =========================
* DOM / Text Helpers
* ========================= */
const isEl = (n) => n && n.nodeType === 1;
const isVisible = (el) => {
if (!isEl(el)) return false;
const rect = el.getBoundingClientRect?.();
if (!rect || rect.width === 0 || rect.height === 0) return false;
const st = getComputedStyle(el);
if (st.display === "none" || st.visibility === "hidden" || parseFloat(st.opacity || "1") < 0.05) return false;
return true;
};
const norm = (s) => (s || "")
.replace(/\u2026/g, "...") // ellipsis → three dots
.replace(/[.\s]+$/g, "") // trim trailing dots/spaces
.trim()
.toLowerCase();
function findVisibleEquals(tokens) {
const hits = [];
const nodes = document.querySelectorAll("span,button,[role='button'],div");
let scanned = 0;
for (const el of nodes) {
scanned++;
if (!isVisible(el)) continue;
const txt = norm(el.textContent || "");
if (tokens.some(tok => txt === tok)) {
hits.push(el.closest("button,[role='button']") || el);
}
}
cT(`findVisibleEquals scanned=${scanned} hits=${hits.length} tokens=${tokens.join(",")}`);
return Array.from(new Set(hits));
}
function findVisibleStartsWith(tokens) {
const hits = [];
const nodes = document.querySelectorAll("span,div,button,[role='button']");
let scanned = 0;
for (const el of nodes) {
scanned++;
if (!isVisible(el)) continue;
const txt = norm(el.textContent || "");
if (tokens.some(tok => txt.startsWith(tok))) {
hits.push(el);
}
}
cT(`findVisibleStartsWith scanned=${scanned} hits=${hits.length} tokens=${tokens.join(",")}`);
return Array.from(new Set(hits));
}
const isStopVisible = () => findVisibleEquals(STOP_TEXTS).length > 0;
const isWorkingVisible = () => findVisibleStartsWith(WORKING_TOKENS).length > 0;
const isStreamingNow = () => isStopVisible() || isWorkingVisible();
/* =========================
* SOUND #4 — Airy Harp Up-Gliss (HTMLAudio WAV + WebAudio fallback)
* - Four soft “pluck” notes rising: C5 → E5 → G5 → C6
* - Triangle oscillators with fast attack & gentle decay
* - Subtle global low-pass to keep it airy
* ========================= */
function makeReplitChimeWavDataURL() {
const sr = 44100;
const N = Math.floor(sr * 1.05); // ~1.05s buffer
const data = new Float32Array(N);
// Pluck events
const freqs = [523.25, 659.25, 783.99, 1046.5]; // C5, E5, G5, C6
const starts = [0.00, 0.06, 0.12, 0.18]; // seconds
const A = 0.008; // Attack seconds
const D = 0.22; // Total pluck duration (~decay to near zero)
const amp = 0.62; // per-note peak
const tri = (x) => (2 / Math.PI) * Math.asin(Math.sin(x));
for (let n = 0; n < freqs.length; n++) {
const f = freqs[n];
const startIdx = Math.floor(starts[n] * sr);
const len = Math.floor(D * sr);
for (let i = 0; i < len && (startIdx + i) < N; i++) {
const t = i / sr;
// Envelope: quick attack → gentle exponential decay
let env;
if (t < A) {
env = t / A;
} else {
const tau = 0.10; // decay constant
env = Math.exp(-(t - A) / tau);
}
// Triangle pluck
const s = tri(2 * Math.PI * f * t);
data[startIdx + i] += amp * env * s;
}
}
// Simple global low-pass (1st-order IIR) for softness (~4.5 kHz)
const fc = 4500;
const alpha = (2 * Math.PI * fc) / (2 * Math.PI * fc + sr);
let y = 0;
for (let i = 0; i < N; i++) {
const x = data[i];
y = y + alpha * (x - y);
data[i] = y;
}
// Gentle soft clip
for (let i = 0; i < N; i++) {
const v = Math.max(-1, Math.min(1, data[i]));
data[i] = Math.tanh(1.05 * v);
}
// Pack to 16-bit PCM WAV (mono)
const bytes = 44 + N * 2;
const dv = new DataView(new ArrayBuffer(bytes));
let off = 0;
const wStr = (s) => { for (let i = 0; i < s.length; i++) dv.setUint8(off++, s.charCodeAt(i)); };
const w32 = (u) => { dv.setUint32(off, u, true); off += 4; };
const w16 = (u) => { dv.setUint16(off, u, true); off += 2; };
wStr("RIFF"); w32(36 + N * 2); wStr("WAVE");
wStr("fmt "); w32(16); w16(1); w16(1); w32(sr); w32(sr * 2); w16(2); w16(16);
wStr("data"); w32(N * 2);
for (let i = 0; i < N; i++) {
const v = Math.max(-1, Math.min(1, data[i]));
dv.setInt16(off, v < 0 ? v * 0x8000 : v * 0x7FFF, true);
off += 2;
}
// Base64 encode
const u8 = new Uint8Array(dv.buffer);
let b64 = "";
for (let i = 0; i < u8.length; i += 0x8000) {
b64 += btoa(String.fromCharCode.apply(null, u8.subarray(i, i + 0x8000)));
}
return `data:audio/wav;base64,${b64}`;
}
const CHIME_URL = makeReplitChimeWavDataURL();
const primeAudioEl = new Audio(CHIME_URL);
primeAudioEl.preload = "auto";
const AudioCtx = window.AudioContext || window.webkitAudioContext;
let ctx;
const ensureCtx = () => (ctx ||= new AudioCtx());
async function playChime(reason) {
// Primary: HTMLAudio
try {
const a = primeAudioEl.cloneNode();
a.volume = 1.0;
await a.play();
cS(`🔊 Chime (Airy Harp, HTMLAudio) reason=${reason} @ ${nowStr()}`);
return;
} catch (e1) {
cW("HTMLAudio failed; trying WebAudio (Airy Harp)", e1);
}
// Fallback: WebAudio version of Sound #4 (Airy Harp)
try {
const AC = window.AudioContext || window.webkitAudioContext;
const c = window.__rp_ctx || new AC();
window.__rp_ctx = c;
if (c.state !== "running") await c.resume();
const t0 = c.currentTime + 0.02;
// Output chain: low-pass for softness
const out = c.createGain(); out.gain.setValueAtTime(0.85, t0);
const lp = c.createBiquadFilter(); lp.type = "lowpass"; lp.frequency.value = 4500; lp.Q.value = 0.6;
out.connect(lp); lp.connect(c.destination);
const pluck = (time, f) => {
const o = c.createOscillator(); o.type = "triangle"; o.frequency.setValueAtTime(f, time);
const g = c.createGain();
// Envelope: fast attack, gentle decay
g.gain.setValueAtTime(0.0001, time);
g.gain.exponentialRampToValueAtTime(0.6, time + 0.008);
g.gain.exponentialRampToValueAtTime(0.001, time + 0.22);
o.connect(g); g.connect(out);
o.start(time); o.stop(time + 0.25);
};
const freqs = [523.25, 659.25, 783.99, 1046.5]; // C5, E5, G5, C6
let cur = t0;
for (const f of freqs) { pluck(cur, f); cur += 0.06; }
cS(`🔊 Chime (Airy Harp, WebAudio) reason=${reason} @ ${nowStr()}`);
} catch (e2) {
cE("WebAudio play failed", e2);
}
}
// Unlock audio on first interaction/visibility
const unlock = async () => {
try { await primeAudioEl.play(); primeAudioEl.pause(); primeAudioEl.currentTime = 0; cI("Audio unlocked via HTMLAudio"); } catch {}
try { if (AudioCtx) { const c = ensureCtx(); if (c.state !== "running") await c.resume(); cI("AudioContext resumed"); } } catch {}
window.removeEventListener("pointerdown", unlock, true);
window.removeEventListener("keydown", unlock, true);
};
window.addEventListener("pointerdown", unlock, true);
window.addEventListener("keydown", unlock, true);
document.addEventListener("visibilitychange", () => { if (document.visibilityState === "visible") unlock(); });
/* =========================
* FSM (Stop/Working-driven)
* ========================= */
let sid = 0;
let s = null;
let pollId = 0;
let lastStop = false;
let lastWork = false;
const STATE = { IDLE: "IDLE", STREAMING: "STREAMING", DONE: "DONE" };
function startPoll() {
if (pollId) return;
pollId = window.setInterval(tick, POLL_MS);
}
function stopPoll() {
if (pollId) { clearInterval(pollId); pollId = 0; }
}
function armStreaming(origin) {
if (s && s.state !== STATE.DONE) return;
s = { id: ++sid, state: STATE.STREAMING, lastStableStart: 0, sawStreaming: true };
cI(`▶️ STREAMING s#${s.id} (origin=${origin}) @ ${nowStr()}`);
startPoll();
}
function maybeComplete() {
if (!s || s.state === STATE.DONE) return;
const streaming = isStreamingNow();
const now = performance.now();
// Visibility transition logs
const curStop = isStopVisible();
const curWork = isWorkingVisible();
if (curStop !== lastStop) {
cI(`Stop visibility: ${curStop ? "ON" : "OFF"}`);
lastStop = curStop;
}
if (curWork !== lastWork) {
cI(`Working visibility: ${curWork ? "ON" : "OFF"}`);
lastWork = curWork;
}
if (!streaming) {
if (!s.lastStableStart) {
s.lastStableStart = now;
cI(`⏳ Stability window started (${STABILITY_MS}ms)`);
}
const elapsed = now - s.lastStableStart;
if (elapsed >= STABILITY_MS) {
s.state = STATE.DONE;
cS(`DONE s#${s.id} (no Stop & no Working for ${Math.round(elapsed)}ms) @ ${nowStr()}`);
playChime(`s#${s.id}`);
stopPoll();
s = null;
}
} else {
if (s.lastStableStart) cW("Stability reset (streaming reappeared)");
s.lastStableStart = 0;
}
}
function tick() {
const streaming = isStreamingNow();
if (streaming && (!s || s.state === STATE.DONE)) {
armStreaming("tick");
}
if (s && s.state === STATE.STREAMING) {
maybeComplete();
}
}
/* =========================
* Observers & Event hooks
* ========================= */
const obs = new MutationObserver((mutations) => {
let nudge = false;
for (const m of mutations) {
if (m.type === "childList") {
for (const n of [...m.addedNodes, ...m.removedNodes]) {
if (isEl(n)) {
const txt = norm(n.textContent || "");
if (STOP_TEXTS.some(s => txt.includes(s)) || WORKING_TOKENS.some(w => txt.startsWith(w))) { nudge = true; break; }
}
}
} else if (m.type === "attributes") {
const el = m.target;
if (!isEl(el)) continue;
const txt = norm(el.textContent || "");
if (STOP_TEXTS.some(s => txt.includes(s)) || WORKING_TOKENS.some(w => txt.startsWith(w))) { nudge = true; }
}
if (nudge) break;
}
if (nudge) {
cT("Mutation nudged tick()");
tick();
}
});
function start() {
if (!document.body) {
document.addEventListener("DOMContentLoaded", start, { once: true });
return;
}
obs.observe(document.body, {
childList: true,
subtree: true,
attributes: true,
attributeFilter: ["class", "style", "aria-hidden"]
});
startPoll();
cI("Armed (Stop/Working FSM). Will chime when both disappear (stable).");
// Initial state snapshot
lastStop = isStopVisible();
lastWork = isWorkingVisible();
cI(`Initial: Stop=${lastStop} Working=${lastWork}`);
if (lastStop || lastWork) armStreaming("initial");
}
if (document.readyState === "loading") {
document.addEventListener("DOMContentLoaded", start, { once: true });
} else {
start();
}
/* =========================
* Runtime Controls (Console)
* =========================
* window.ReplitPing.setDebug(true|false)
* window.ReplitPing.setTrace(true|false)
* window.ReplitPing.setStability(ms)
* window.ReplitPing.status()
* window.ReplitPing.test()
*/
window.ReplitPing = {
setDebug(v){ DEBUG = !!v; cI(`DEBUG=${DEBUG}`); return DEBUG; },
setTrace(v){ TRACE_SCAN = !!v; cI(`TRACE_SCAN=${TRACE_SCAN}`); return TRACE_SCAN; },
setStability(ms){ STABILITY_MS = Math.max(0, Number(ms)||STABILITY_MS_DEFAULT); cI(`STABILITY_MS=${STABILITY_MS}`); return STABILITY_MS; },
status(){
const streaming = isStreamingNow();
const state = s ? s.state : STATE.IDLE;
const info = {
state,
sessionId: s?.id ?? null,
stopVisible: isStopVisible(),
workingVisible: isWorkingVisible(),
streaming,
stabilityMs: STABILITY_MS,
pollActive: !!pollId,
time: nowStr(),
};
cI("Status", info);
return info;
},
async test(){ await playChime("manual-test"); return true; }
};
})();
A tool for importing from Google Docs that doesn’t suck (Mammoth .docx converter)
I was tired of WordPress’s crappy editor so I decided to write a post in Google Docs instead.
However, when copying the content back in. All the images I carefully added did not carry back over. After trying several terrible options (Seraphinite Post .DOCX Source, WordPress.com for Google Docs, docswrite.com — this didn’t work when I tried but seems to function fine after going back and forth with their CEO) I finally tried out Mammoth and it just works which is great.
- Add a post
- Look for the Mammoth .docx converter box at the bottom
- Upload your file
- Wait for it to parse
- Click on Insert into editor
- And then wait for it to finish adding all the content into the editor (my docx took a few minutes since it had quite a few high resolution images)


Japan Recommendations
A quick note on the below content. All of the things I’ve included I personally enjoyed greatly and would enjoy to anyone who shares my tastes. Have fun in Japan!
Tokyo
Tokyo food
- L’Effervescence


- Oniku Karyu
- Cokuun (Coffee Omakase)
- I’m Donut ?
- Pizza Bar


- Cycle
- IPPUKU&MATCHA

- Blue Bottle Cafe (surprisingly good Matcha Latte)

- Parklet Bakery


- Iki Expresso


- Le Petit Mec Hibiya (the best pastries I’ve had in Tokyo)

Tokyo things to do
- Nezu Museum

- Hamarikyu Gardens



- Ueno Park (come at golden hour)



- Tokyo National Museum
- Teamlabs Borderless
- Teamlabs Planets
Kyoto
Kyoto Food
- Akagakiya

Kyoto things to do
- Kyoto Golden Temple
- Otagi Nenbutsuji Temple
- Arashiyama Bamboo Grove (make sure you hike up into the park by the Bamboo Grove for the Valley View!)
- Mt Inari (go early and hike to the top)
- Kiyomizu-dera Temple (this was the most spectacular temple that I visited)

- Ruriko-in Temple

Osaka
Osaka Food
Osaka Things to do
- Osaka Castle (go at sunrise, its spectacular!)
Other places
Lake Kawaguchi

Onomichi
- Shinomani-Kaido

Himeji
- Himeji Castle



Wakayama
- Tatago Rock

Nara
- Nara Park


Nikko
- Kinfuri Falls


- Shinkyo Bridge


- Nikko Tamozawa Imperial Villa Memorial Park




- Nikkō Tōshogū


Tokyo
Tokyo food
- L’Effervescence


- Oniku Karyu
- Cokuun (Coffee Omakase)
- I’m Donut ?
- Pizza Bar


- Cycle
- IPPUKU&MATCHA

- Blue Bottle Cafe (surprisingly good Matcha Latte)

- Parklet Bakery


- Iki Expresso


- Le Petit Mec Hibiya (the best pastries I’ve had in Tokyo)

Tokyo things to do
- Nezu Museum

- Hamarikyu Gardens



- Ueno Park (come at golden hour)



- Tokyo National Museum
- Teamlabs Borderless
- Teamlabs Planets
Kyoto
Kyoto Food
- Akagakiya

Kyoto things to do
- Kyoto Golden Temple
- Otagi Nenbutsuji Temple
- Arashiyama Bamboo Grove (make sure you hike up into the park by the Bamboo Grove for the Valley View!)
- Mt Inari (go early and hike to the top)
- Kiyomizu-dera Temple (this was the most spectacular temple that I visited)

- Ruriko-in Temple

Osaka
Osaka Food
Osaka Things to do
- Osaka Castle (go at sunrise, its spectacular!)
Other places
Lake Kawaguchi

Onomichi
- Shinomani-Kaido

Himeji
- Himeji Castle



Wakayama
- Tatago Rock

Nara
- Nara Park


Nikko
- Kinfuri Falls


- Shinkyo Bridge


- Nikko Tamozawa Imperial Villa Memorial Park




- Nikkō Tōshogū


Tokyo
Tokyo food
- L’Effervescence


- Oniku Karyu
- Cokuun (Coffee Omakase)
- I’m Donut ?
- Pizza Bar


- Cycle
- IPPUKU&MATCHA

- Blue Bottle Cafe (surprisingly good Matcha Latte)

- Parklet Bakery


- Iki Expresso


- Le Petit Mec Hibiya (the best pastries I’ve had in Tokyo)

Tokyo things to do
- Nezu Museum

- Hamarikyu Gardens



- Ueno Park (come at golden hour)



- Tokyo National Museum
- Teamlabs Borderless
- Teamlabs Planets
Kyoto
Kyoto Food
- Akagakiya

Kyoto things to do
- Kyoto Golden Temple
- Otagi Nenbutsuji Temple
- Arashiyama Bamboo Grove (make sure you hike up into the park by the Bamboo Grove for the Valley View!)
- Mt Inari (go early and hike to the top)
- Kiyomizu-dera Temple (this was the most spectacular temple that I visited)

- Ruriko-in Temple

Osaka
Osaka Food
Osaka Things to do
- Osaka Castle (go at sunrise, its spectacular!)
Other places
Lake Kawaguchi

Onomichi
- Shinomani-Kaido

Himeji
- Himeji Castle



Wakayama
- Tatago Rock

Nara
- Nara Park


Nikko
- Kinfuri Falls


- Shinkyo Bridge


- Nikko Tamozawa Imperial Villa Memorial Park




- Nikkō Tōshogū


ChatGPT Chime on Chat Completion (Tampermonkey Script)
Tampermonkey script
// ==UserScript==
// @name ChatGPT Completion Ping (Composer FSM, background-safe, no-timeout)
// @namespace nicholas.tools
// @version 5.4.0
// @description Chime on completion even when window/tab isn't focused. No timeout; FSM: saw Stop → Stop gone + editor empty. Poll + resilient audio.
// @match https://chat.openai.com/*
// @match https://chatgpt.com/*
// @grant none
// @run-at document-idle
// ==/UserScript==
(() => {
"use strict";
/* =========================
* Logging
* ========================= */
const DEBUG = true;
const log = (...a) => DEBUG && console.log("[COMP-PING]", ...a);
const t = () => new Date().toLocaleTimeString();
/* =========================
* Selectors (composer only)
* ========================= */
const COMPOSER_EDITABLE = '#prompt-textarea.ProseMirror[contenteditable="true"]';
const COMPOSER_FALLBACK_TA = 'textarea[name="prompt-textarea"]';
const SEND_BTN = '#composer-submit-button[data-testid="send-button"]';
const STOP_BTN = '#composer-submit-button[data-testid="stop-button"]';
/* =========================
* Audio: HTMLAudio primary (WAV data URL), WebAudio fallback
* ========================= */
function makeChimeWavDataURL() {
const sr = 44100, dur = 0.99;
const notes = [
{ f: 987.77, d: 0.22 }, { f: 1318.51, d: 0.22 },
{ f: 1174.66, d: 0.20 }, { f: 1318.51, d: 0.30 },
];
const gap = 0.055, amp = 0.28;
const N = Math.floor(sr * dur);
const data = new Float32Array(N).fill(0);
let t0 = 0;
for (const { f, d } of notes) {
const nSamp = Math.floor(d * sr);
const start = Math.floor(t0 * sr);
for (let i = 0; i < nSamp && start + i < N; i++) {
const env = i < 0.01*sr ? i/(0.01*sr) : (i > nSamp-0.03*sr ? Math.max(0, (nSamp - i)/(0.03*sr)) : 1);
const s = Math.sin(2*Math.PI*f*(i/sr));
const s2 = Math.sin(2*Math.PI*(f*1.005)*(i/sr)) * 0.6;
data[start+i] += amp * env * (0.7*s + 0.3*s2);
}
t0 += d + gap;
}
const pcm = new DataView(new ArrayBuffer(44 + N*2));
let off = 0;
const wStr = (s) => { for (let i=0;i<s.length;i++) pcm.setUint8(off++, s.charCodeAt(i)); };
const w32 = (u) => { pcm.setUint32(off, u, true); off+=4; };
const w16 = (u) => { pcm.setUint16(off, u, true); off+=2; };
wStr("RIFF"); w32(36 + N*2); wStr("WAVE");
wStr("fmt "); w32(16); w16(1); w16(1); w32(sr); w32(sr*2); w16(2); w16(16);
wStr("data"); w32(N*2);
for (let i=0;i<N;i++) { const v = Math.max(-1, Math.min(1, data[i])); pcm.setInt16(off, v<0?v*0x8000:v*0x7FFF, true); off+=2; }
const u8 = new Uint8Array(pcm.buffer);
const b64 = btoa(String.fromCharCode(...u8));
return `data:audio/wav;base64,${b64}`;
}
const CHIME_URL = makeChimeWavDataURL();
const primeAudioEl = new Audio(CHIME_URL);
primeAudioEl.preload = "auto";
const AudioCtx = window.AudioContext || window.webkitAudioContext;
let ctx;
const ensureCtx = () => (ctx ||= new AudioCtx());
async function playChime(reason) {
try {
const a = primeAudioEl.cloneNode();
a.volume = 1.0;
await a.play();
log(`🔊 DONE (HTMLAudio) ${reason} @ ${t()}`);
return;
} catch {}
try {
const c = ensureCtx();
if (c.state !== "running") await c.resume();
const t0 = c.currentTime + 0.02;
const master = c.createGain(); master.gain.setValueAtTime(0.9, t0); master.connect(c.destination);
const lp = c.createBiquadFilter(); lp.type="lowpass"; lp.frequency.value=4200; lp.Q.value=0.6; lp.connect(master);
const delay = c.createDelay(0.5); delay.delayTime.value=0.18;
const fb = c.createGain(); fb.gain.value=0.22; delay.connect(fb); fb.connect(delay); delay.connect(master);
const bus = c.createGain(); bus.gain.value=0.85; bus.connect(lp); bus.connect(delay);
const seq = [
{ f: 987.77, d: 0.22 }, { f: 1318.51, d: 0.22 },
{ f: 1174.66, d: 0.20 }, { f: 1318.51, d: 0.30 },
];
let cur = t0, gap = 0.055;
for (const {f,d} of seq) {
const o1=c.createOscillator(), g1=c.createGain(); o1.type="triangle"; o1.frequency.value=f;
g1.gain.setValueAtTime(0.0001,cur); g1.gain.exponentialRampToValueAtTime(0.6,cur+0.01); g1.gain.exponentialRampToValueAtTime(0.001,cur+d);
o1.connect(g1); g1.connect(bus); o1.start(cur); o1.stop(cur+d+0.02);
const o2=c.createOscillator(), g2=c.createGain(); o2.type="sine"; o2.frequency.setValueAtTime(f*1.005,cur);
g2.gain.setValueAtTime(0.0001,cur); g2.gain.exponentialRampToValueAtTime(0.35,cur+0.012); g2.gain.exponentialRampToValueAtTime(0.001,cur+d);
o2.connect(g2); g2.connect(bus); o2.start(cur); o2.stop(cur+d+0.02);
cur += d + gap;
}
log(`🔊 DONE (WebAudio) ${reason} @ ${t()}`);
} catch {}
}
// Prime on user interaction
const unlock = async () => {
try { await primeAudioEl.play(); primeAudioEl.pause(); primeAudioEl.currentTime = 0; } catch {}
try { if (AudioCtx) { const c = ensureCtx(); if (c.state !== "running") await c.resume(); } } catch {}
window.removeEventListener("pointerdown", unlock, true);
window.removeEventListener("keydown", unlock, true);
};
window.addEventListener("pointerdown", unlock, true);
window.addEventListener("keydown", unlock, true);
document.addEventListener("visibilitychange", () => { if (document.visibilityState === "visible") unlock(); });
/* =========================
* Composer helpers
* ========================= */
const isEl = (n) => n && n.nodeType === 1;
const visible = (sel) => { const el = document.querySelector(sel); return !!(el && el.offsetParent !== null); };
const editorEl = () => document.querySelector(COMPOSER_EDITABLE) || document.querySelector(COMPOSER_FALLBACK_TA) || null;
function editorEmpty() {
const el = editorEl();
if (!el) return true;
if (el.matches('textarea')) return (el.value || '').replace(/\u200b/g,'').trim().length === 0;
const txt = (el.textContent || '').replace(/\u200b/g,'').trim();
return txt.length === 0;
}
const isStopVisible = () => visible(STOP_BTN);
/* =========================
* FSM + background-safe polling (NO TIMEOUT)
* ========================= */
let sid = 0;
let s = null;
let pollId = 0;
const STATE = { IDLE:'IDLE', ARMED:'ARMED', CLEARED:'CLEARED', STREAMING:'STREAMING', DONE:'DONE' };
function stopPoll() { if (pollId) { clearInterval(pollId); pollId = 0; } }
function startPoll() {
stopPoll();
// steady 250ms poll; browsers may throttle in background which is fine
pollId = window.setInterval(() => tick(true), 250);
}
function cancelSession(reason) {
if (!s) return;
log(`CANCEL s#${s.id} (${reason})`);
stopPoll();
s = null;
}
function arm(reason) {
// Cancel any previous session (no timeout; avoid multiple active)
if (s) cancelSession("re-ARM");
s = {
id: ++sid,
state: STATE.ARMED,
sawStop: false,
sawCleared: editorEmpty(),
lastStopGoneAt: 0
};
log(`ARM s#${s.id} (${reason}) empty=${s.sawCleared} stop=${isStopVisible()} @ ${t()}`);
startPoll();
tick();
}
function transition(newState, why) {
if (!s || s.state === STATE.DONE) return;
if (s.state !== newState) {
s.state = newState;
log(`${newState} s#${s.id} (${why}) empty=${editorEmpty()} stop=${isStopVisible()} @ ${t()}`);
}
}
function evaluate() {
if (!s || s.state === STATE.DONE) return;
// Editor cleared after send
if (!s.sawCleared && editorEmpty()) {
s.sawCleared = true;
transition(STATE.CLEARED, "editor cleared");
}
// Streaming seen
if (!s.sawStop && isStopVisible()) {
s.sawStop = true;
transition(STATE.STREAMING, "stop visible");
}
// Stop disappears
if (s.sawStop && !isStopVisible() && !s.lastStopGoneAt) {
s.lastStopGoneAt = performance.now();
log(`STOP-GONE s#${s.id} (detected)`);
}
// Completion: saw Stop once AND Stop gone AND editor empty (150ms stability)
if (s.sawStop && !isStopVisible() && editorEmpty()) {
const stable = s.lastStopGoneAt ? (performance.now() - s.lastStopGoneAt) : 999;
if (stable >= 150) {
transition(STATE.DONE, "stop gone + editor empty");
playChime(`s#${s.id}`);
stopPoll();
s = null;
}
}
}
const tick = () => { evaluate(); };
/* =========================
* Events & Observers
* ========================= */
document.addEventListener("click", (e) => {
const btn = isEl(e.target) ? e.target.closest(SEND_BTN) : null;
if (!btn) return;
arm("send-button click");
}, true);
document.addEventListener("keydown", (e) => {
const ed = isEl(e.target) && (e.target.closest(COMPOSER_EDITABLE) || e.target.closest(COMPOSER_FALLBACK_TA));
if (!ed) return;
if (e.key !== "Enter" || e.shiftKey || e.altKey || e.ctrlKey || e.metaKey || e.isComposing) return;
if (document.querySelector(SEND_BTN)) arm("keyboard Enter");
}, true);
const obs = new MutationObserver((mutations) => {
if (!s) return;
for (const m of mutations) {
if (m.type === "attributes") {
const el = m.target;
if (isEl(el) && (el.id === "composer-submit-button" || el.matches(COMPOSER_EDITABLE) || el.matches(COMPOSER_FALLBACK_TA))) {
tick();
}
}
if (m.type === "childList") {
for (const n of m.addedNodes) {
if (!isEl(n)) continue;
if (n.matches(STOP_BTN) || n.matches(SEND_BTN) ||
n.querySelector?.(STOP_BTN) || n.querySelector?.(SEND_BTN) ||
n.matches(COMPOSER_EDITABLE) || n.matches(COMPOSER_FALLBACK_TA) ||
n.querySelector?.(COMPOSER_EDITABLE) || n.querySelector?.(COMPOSER_FALLBACK_TA)) {
tick();
break;
}
}
for (const n of m.removedNodes) {
if (!isEl(n)) continue;
if (n.matches(STOP_BTN) || n.matches(SEND_BTN) ||
n.matches(COMPOSER_EDITABLE) || n.matches(COMPOSER_FALLBACK_TA)) {
tick();
break;
}
}
}
if (m.type === "characterData") tick();
}
});
function start() {
obs.observe(document.body, {
childList: true,
subtree: true,
attributes: true,
attributeFilter: ["data-testid","id","class","style","contenteditable","value"],
characterData: true
});
log("armed (composer FSM, background-safe, no-timeout). Completes on: saw Stop → Stop gone + editor empty.");
}
if (document.readyState === "loading") {
document.addEventListener("DOMContentLoaded", start, { once: true });
} else {
start();
}
})();
Go actual full screen on Simplepractice.com video calls
When I’m on calls with my therapist it has bugged me that I can’t actually go fullscreen with the video so I gave CGPT the code for the page and wrote up a script that expands the fullscreen video to actually be fullscreen.
Use either the console script or Tampermonkey script and try it out for yourself!

Console script
(() => {
const TOGGLE = 'tm-full-bleed-active';
const ROOT_SEL = 'div.bbwWj.video';
const PANEL_SEL = `${ROOT_SEL} > div.mljTO`;
const STREAM_CONTAINER_SEL = `${ROOT_SEL} .stream-container`;
const PARTICIPANT_SEL = `${ROOT_SEL} .participant-container`;
const VIDEO_SEL = `${ROOT_SEL} video`;
// --- style injection ---
const css = `
html.${TOGGLE}, body.${TOGGLE}{margin:0!important;padding:0!important;overflow:hidden!important}
html.${TOGGLE} ${PANEL_SEL}{
position:fixed!important;inset:0!important;width:100vw!important;height:100vh!important;
margin:0!important;padding:0!important;border:0!important;background:#000!important;
z-index:2147483647!important;box-shadow:none!important
}
html.${TOGGLE} ${STREAM_CONTAINER_SEL}, html.${TOGGLE} ${PARTICIPANT_SEL}{
position:absolute!important;inset:0!important;width:100%!important;height:100%!important;
margin:0!important;padding:0!important;border:0!important;max-width:none!important;max-height:none!important;overflow:hidden!important;background:transparent!important
}
html.${TOGGLE} ${VIDEO_SEL}{
position:absolute!important;inset:0!important;width:100%!important;height:100%!important;
object-fit:cover!important;object-position:center center!important;display:block!important;background:#000!important;border:0!important;box-shadow:none!important;transform:none!important
}
html.${TOGGLE} ${ROOT_SEL} .name, html.${TOGGLE} ${ROOT_SEL} .pin-button, html.${TOGGLE} ${ROOT_SEL} .more-button{
display:none!important;visibility:hidden!important;pointer-events:none!important
}
.tm-fb-btn{
position:fixed!important;right:14px;bottom:14px;z-index:2147483647!important;
font:600 12px/1 system-ui,-apple-system,Segoe UI,Roboto,Helvetica,Arial,sans-serif;
padding:10px 12px;border-radius:999px;background:rgba(0,0,0,.6);color:#fff;
border:1px solid rgba(255,255,255,.2);cursor:pointer;user-select:none;backdrop-filter:blur(4px)
}
.tm-fb-btn:hover{background:rgba(0,0,0,.75)}
`;
let style = document.getElementById('tm-fb-style');
if (!style) {
style = document.createElement('style');
style.id = 'tm-fb-style';
style.textContent = css;
document.head.appendChild(style);
}
// --- helpers ---
const $ = (s, r = document) => r.querySelector(s);
const nap = (ms) => new Promise(r => setTimeout(r, ms));
const waitFor = async (sel, tries = 200, step = 100) => {
while (tries-- > 0) { const el = $(sel); if (el) return el; await nap(step); }
return null;
};
// --- state ---
let btn;
const isActive = () =>
document.documentElement.classList.contains(TOGGLE) ||
document.body.classList.contains(TOGGLE);
const setActive = (on) => {
[document.documentElement, document.body].forEach(el => el && el.classList.toggle(TOGGLE, on));
if (btn) btn.textContent = on ? 'Exit Full-Bleed' : 'Full-Bleed';
};
const toggle = () => setActive(!isActive());
// --- UI button ---
const mountButton = () => {
if (btn && document.body.contains(btn)) return btn;
btn = document.createElement('button');
btn.className = 'tm-fb-btn';
btn.type = 'button';
btn.textContent = isActive() ? 'Exit Full-Bleed' : 'Full-Bleed';
btn.addEventListener('click', toggle);
document.body.appendChild(btn);
return btn;
};
// --- key bindings ---
const bindKeys = () => {
window.addEventListener('keydown', (e) => {
if (e.key === 'f' || e.key === 'F') { e.preventDefault(); toggle(); }
else if (e.key === 'Escape' && isActive()) { e.preventDefault(); setActive(false); }
}, { capture: true });
};
// --- dblclick on video ---
const bindVideoDblClick = (v) => {
if (!v || v.dataset.tmFbBound) return;
v.addEventListener('dblclick', (e) => { e.preventDefault(); toggle(); }, { capture: true });
v.dataset.tmFbBound = '1';
};
// --- observe dynamic DOM ---
const observe = () => {
const mo = new MutationObserver(() => {
const v = $(VIDEO_SEL);
if (v) bindVideoDblClick(v);
if (!btn && document.body) mountButton();
});
mo.observe(document.documentElement, { childList: true, subtree: true });
};
// --- bootstrap ---
(async () => {
await waitFor('body');
bindKeys();
observe();
const v = await waitFor(VIDEO_SEL, 120, 150);
if (v) bindVideoDblClick(v);
mountButton();
// Expose controls for manual use
window.tmFullBleed = { toggle, on: () => setActive(true), off: () => setActive(false) };
console.log('[tmFullBleed] Ready. Use tmFullBleed.toggle(), press F, double-click video, or use the button.');
})();
})();
Tampermonkey script
// ==UserScript==
// @name Full-Bleed Video (SimplePractice only)
// @namespace nic.tools.video
// @version 1.0.1
// @description Force main video to go true full-bleed (edge-to-edge) on SimplePractice video
// @author you
// @match https://video.simplepractice.com/*
// @run-at document-idle
// @grant GM_addStyle
// ==/UserScript==
(function () {
'use strict';
// ---------- small utils ----------
const nap = (ms) => new Promise(r => setTimeout(r, ms));
const q = (sel, root = document) => root.querySelector(sel);
// Wait for an element or return null after tries*interval
const waitFor = async (fnOrSel, tries = 200, interval = 100) => {
while (tries-- > 0) {
let el = null;
try { el = typeof fnOrSel === 'function' ? fnOrSel() : q(fnOrSel); } catch {}
if (el) return el;
await nap(interval);
}
return null;
};
// ---------- selectors from provided markup ----------
const ROOT_SEL = 'div.bbwWj.video';
const PANEL_SEL = `${ROOT_SEL} > div.mljTO`;
const STREAM_CONTAINER_SEL = `${ROOT_SEL} .stream-container`;
const PARTICIPANT_SEL = `${ROOT_SEL} .participant-container`;
const VIDEO_SEL = `${ROOT_SEL} video`;
const TOGGLE_CLASS = 'tm-full-bleed-active';
// ---------- inject styles ----------
GM_addStyle(`
/* Full-bleed mode root locks */
html.${TOGGLE_CLASS}, body.${TOGGLE_CLASS} {
margin: 0 !important;
padding: 0 !important;
overflow: hidden !important;
}
/* Pin the main panel to the viewport */
html.${TOGGLE_CLASS} ${PANEL_SEL} {
position: fixed !important;
inset: 0 !important;
width: 100vw !important;
height: 100vh !important;
margin: 0 !important;
padding: 0 !important;
border: 0 !important;
background: #000 !important;
z-index: 2147483647 !important;
box-shadow: none !important;
}
/* Ensure no intermediate wrapper constrains size */
html.${TOGGLE_CLASS} ${STREAM_CONTAINER_SEL},
html.${TOGGLE_CLASS} ${PARTICIPANT_SEL} {
position: absolute !important;
inset: 0 !important;
width: 100% !important;
height: 100% !important;
margin: 0 !important;
padding: 0 !important;
border: 0 !important;
max-width: none !important;
max-height: none !important;
overflow: hidden !important;
background: transparent !important;
}
/* Make the video fill and crop (letterboxing avoidance) */
html.${TOGGLE_CLASS} ${VIDEO_SEL} {
position: absolute !important;
inset: 0 !important;
width: 100% !important;
height: 100% !important;
object-fit: cover !important;
object-position: center center !important;
display: block !important;
background: #000 !important;
border: 0 !important;
box-shadow: none !important;
transform: none !important;
}
/* Hide overlays that might intrude (adjust as needed) */
html.${TOGGLE_CLASS} ${ROOT_SEL} .name,
html.${TOGGLE_CLASS} ${ROOT_SEL} .pin-button,
html.${TOGGLE_CLASS} ${ROOT_SEL} .more-button {
display: none !important;
visibility: hidden !important;
pointer-events: none !important;
}
/* On-screen toggle button */
.tm-fb-btn {
position: fixed !important;
right: 14px;
bottom: 14px;
z-index: 2147483647 !important;
font: 600 12px/1 system-ui, -apple-system, Segoe UI, Roboto, Helvetica, Arial, sans-serif;
padding: 10px 12px;
border-radius: 999px;
background: rgba(0,0,0,0.6);
color: #fff;
border: 1px solid rgba(255,255,255,0.2);
cursor: pointer;
user-select: none;
backdrop-filter: blur(4px);
}
.tm-fb-btn:hover { background: rgba(0,0,0,0.75); }
`);
// ---------- toggle logic ----------
const setActive = (on) => {
const rootList = [document.documentElement, document.body].filter(Boolean);
rootList.forEach(el => el.classList.toggle(TOGGLE_CLASS, on));
if (btn) btn.textContent = on ? 'Exit Full-Bleed' : 'Full-Bleed';
};
const isActive = () =>
document.documentElement.classList.contains(TOGGLE_CLASS) ||
document.body.classList.contains(TOGGLE_CLASS);
const toggle = () => setActive(!isActive());
// ---------- button ----------
let btn;
const mountButton = () => {
if (btn && document.body.contains(btn)) return btn;
btn = document.createElement('button');
btn.className = 'tm-fb-btn';
btn.type = 'button';
btn.textContent = isActive() ? 'Exit Full-Bleed (f)' : 'Full-Bleed (f)';
btn.addEventListener('click', toggle);
document.body.appendChild(btn);
return btn;
};
// ---------- event bindings ----------
const bindKeys = () => {
window.addEventListener('keydown', (e) => {
if (e.key === 'f' || e.key === 'F') {
e.preventDefault();
toggle();
} else if (e.key === 'Escape' && isActive()) {
e.preventDefault();
setActive(false);
}
}, { capture: true });
};
const bindVideoDoubleClick = (video) => {
if (!video || video.dataset.tmFbBound) return;
video.addEventListener('dblclick', (e) => {
e.preventDefault();
toggle();
}, { capture: true });
video.dataset.tmFbBound = '1';
};
// ---------- observer to reapply on dynamic pages ----------
const observe = () => {
const mo = new MutationObserver(() => {
const video = q(VIDEO_SEL);
if (video) bindVideoDoubleClick(video);
if (!btn && document.body) mountButton();
});
mo.observe(document.documentElement, { childList: true, subtree: true, attributes: false });
};
// ---------- bootstrap ----------
(async () => {
await waitFor(() => document.body);
bindKeys();
observe();
const video = await waitFor(VIDEO_SEL, 120, 150);
if (video) bindVideoDoubleClick(video);
mountButton();
// Optional: expose console controls
window.tmFullBleed = { toggle, on: () => setActive(true), off: () => setActive(false) };
console.log('[tmFullBleed] Ready on SimplePractice. Use tmFullBleed.toggle(), press F, double-click video, or use the button.');
})();
})();
See my creation conversation with ChatGPT here:
https://chatgpt.com/share/68c89780-f700-8007-916b-2d707b1970a6
Fix for audio cutting out for 1-3 seconds randomly with MSI B650-S Wifi Motherboard
If your sound keeps cutting out seemingly randomly for your wirelessly headset with this motherboard then try plugging it into the other USB slots (not the blue ones, the red ones). It seems to have fixed my issue. Seems the other ones may not have enough power to support the power draw.
Found the fix here: Audio issues MSI Pro B650-S Wifi | MSI Global English Forum
Have you use another headphone to check for the symptom?
I think I found the solution to my issue :
The USB 3.2 Gen 1 ports connect to something called “Hub-1074” and I guess those aren’t good enough for USB headsets. I at first thought that it was an issue with the board because the chipset driver updates reduced the problem, but didn’t fix it. I then tried connecting with a different headset that uses 3.5mm jacks and it worked without issues, so now I have connected my USB headset to one of the USB 3.2 Gen 2 ports that connect to the CPU, and so far I haven’t had any audio issues.
My Favourite Podcasts!
Podcasts are one of my favourite ways to learn and entertain myself. Here are some of my faves from over the years.
- Planet Money / The Indicator
- Fairly light podcast on economics, very engaging hosts, interesting topics.
- This American Life
- A classic, beautiful stories on being human.
- 99% Invisible
- Learn awesome things about design and little details in life you wouldn’t have otherwise discovered.
- Rumble Strip
- Very direct, down to earth stories about everyday Vermonters. Especially love the ones with her farmer friend or town hall meetings. Note, I hate about 25% of the episodes as she’ll have random guest episodes and they can be awful.
- What Roman Mars Can Learn About Con Law
- Get into the minutia of constitutional law with Roman Mars and his law professor friend.
- Twenty Thousand Hertz
- The most beautifully podcast I’ve ever listened to. Amazing stories about audio in many different ways and a surprisingly genuine and warm. host.
- The Big Dig
- Ever wanted to find out exactly what went wrong in so many ways with a mega project in the United States? This podcast goes into the details on the many trials and tribulations of the Big Dig project in Boston. I learned a lot and it was super interesting!
- Acquired
- Listen to this if you’re interested in going in deep on companies. The hosts go on multi hour deep dives into the histories of the companies they cover. I find it to be super helpful for understanding how companies came to be but also what differentiates them from other companies.
- Search Engine
- In depth episodes on a very wide range of topics (the secret pool in Buckingham Palace, people who buy luggage at the airport, jawmaxxing) which I find very interesting and delightful in their unnecessary depth.
- The Sporkful
- Nice stories about food. The host’s speaking style isn’t my favourite and some of the episodes are a little meh but there are enough good ones in there to make it worthwhile.
- Startup
- Front row seats to creation and development over the years of Gimlet. Really fascinating glimpse into the birth of a company (and all the various things that come with it).
- Reply All
- One of Gimlet’s first successful podcasts, now retired due to a messy series of events but lots of fun and interesting episodes before that happened.
- Heavyweight
- Heartwarming and humanistic stories about the host trying to help a given guest try and resolve a deep seated relationship issue. Personally, I find the non-mainline episodes annoying but the standard episodes are great!
- More Perfect
- An awesomely in depth podcast series on how the Supreme Court works and some of their historic decisions. If you have any interest in the way the American legal system functions I wholeheartedly recommend this podcast.
- The Disconnect
- Want to spend 10+ hours learning about how Texas’s energy grid functions and why it failed? This is the podcast for you, :).
- The End of the World (with Josh Clark)
- Quite different from most podcasts out there. This one touches on a number of far far future scenarios and feels very sci fi at times. Excellent production and you’ll probably learn a few new concepts.
- The Last Cup
- Detailed storytelling surrounding Messi’s final world cup run and all the drama leading up to it. As a fan of Messi this was great to listen to plus it has a very satisfying end.
- Gamecraft
- One of Benchmark’s legendary GPs breaks down the economics and structure of the gaming industry piece by piece. Incredible knowledge contained within. Great if you’re interested in the business of gaming.
- The Secret Life of Canada
- Stories told about the often untold side of things from a indigenous perspective in Canada. A mix of humour and learning about horrific events you’ll likely learn a lot about things you didn’t know happened. The hosts have excellent chemistry with each other and do a fantastic job of covering the subject matter in a way that doesn’t shy away from the facts but also doesn’t leave you feeling irredeemably depressed.
- Lenny’s Podcast
- The best product podcast out there. Learn about a whole range of product related topics and from some of the strongest operators out there. When I feel like learning more about my craft I listen to this, :).
- Containers
- In depth coverage of the systems that power our ports (and how they’ve changed over time). The storytelling here is excellent and you’ll learn a lot about how goods move around the world.
How to get Tablepress tables to show in full width
- Go to Appearance –> Customize –> Additional CSS
(If you’re in the right place, this should show after your site URL /wp-admin/customize.php)
2. Add in this CSS block modification
.content-area__wrapper {
–go–max-width: 100rem;
}
3. Now your tables will show at full width on your site!
If you want it to only apply to a specific page, publish your page, go to that page, right click to inspect and find out the page ID (it shows at the very top), then target your change to only apply to that page in your Additional CSS settings.
In my case, my page ID is 534 so I did the following
.page-id-534 .content-area__wrapper {
–go–max-width: 100rem;
}
Make sure you include a space between .page-id-534 and .content-area__wrapper
Here’s a screenshot of what my inspect view looked like.

How to build & check to see if your ads.txt file is correct for Google Ads (Adsense)
Your ads.txt file is composed of the following parts
For example: google.com, pub-XXXXXXXXXXXXXXXX, DIRECT, f08c47fec0942fa0
Where:
- “google.com” is the advertising system domain
- “pub-XXXXXXXXXXXXXXXX” is your unique publisher ID
- “DIRECT” indicates a direct business relationship
- “f08c47fec0942fa0” is Google’s AdSystem ID
So to create your own ads.txt, all you need to do is go to your account information page (Account information – Settings – Account – Google AdSense) and pull your publisher ID and slot it in.
Once you’ve got your ads.txt file set up on your website (I used Ads.txt Manager – WordPress plugin | WordPress.org for this).
When its added in, you can check to see if its showing up properly by visiting website.com/ads.txt (in my case pezant.ca/ads.txt)
Or if you want to, you can also use this tool which works well!
ads.txt Validator – Free ads.txt Validation Tool by ads.txt Guru (adstxt.guru)
Updating your wordpress PW without being able to password reset via email (GCP hosted WordPress instance)
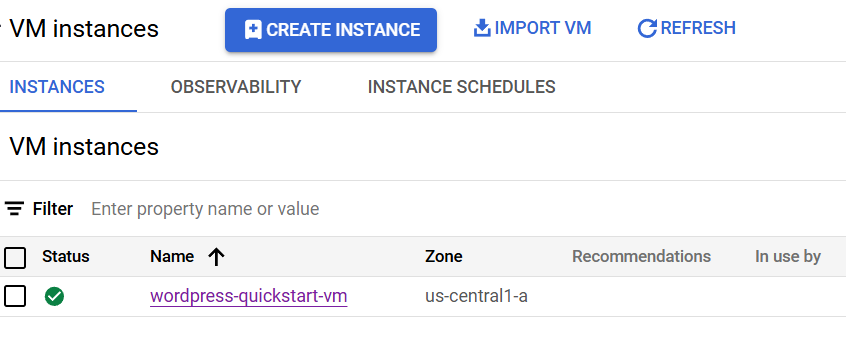
Steps:
- Get to your VM instance page (https://console.cloud.google.com/compute/instances)
- Click on the SSH dropdown
- Enter the following commands
~$ cd /var/www/html
/var/www/html$ wp user update [username] –user_pass=[new_password]
Here’s an example if your user name was “admin” and you wanted the password to be “new_pass” you would enter the following after navigating to the right directory.
wp user update admin –user_pass=new_pass
Here’s the SSH button if you don’t know where to find it

Getting iframes to appear centered for WordPress pages/posts
I recently set up a few iframes and they were stubbornly left aligned despite all the other content being center aligned. Here’s how I was able to fix the issue.
- Go to Appearance –> Customize –> Additional CSS (/wp-admin/customize.php)
- Add this value to your custom CSS
iframe {
display: block;
margin: 0 auto;
}
3. Hit publish and you should be good!

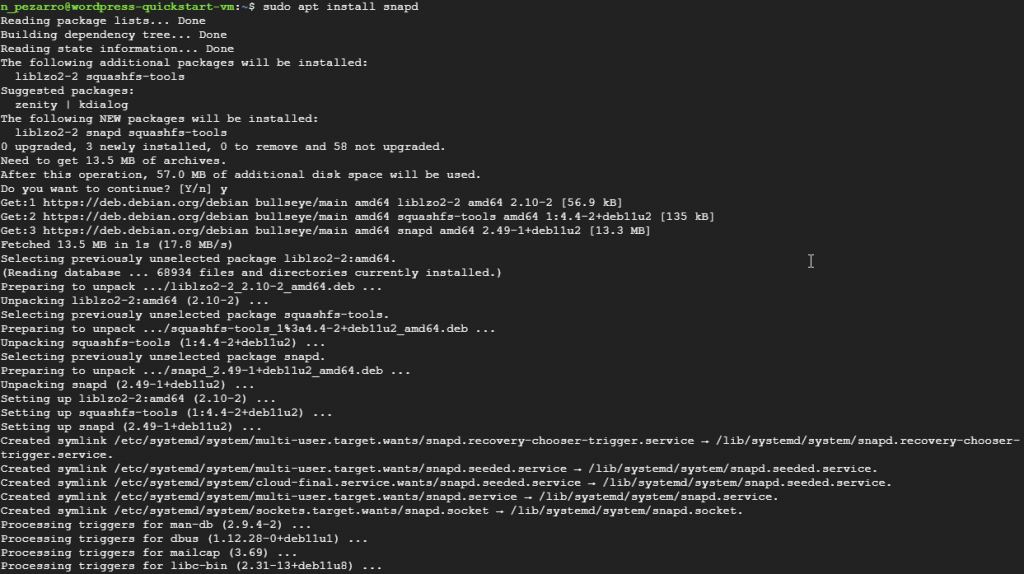
Install snapd on Google Cloud Platform VM
- Go to your VM instance page
- Connect to the VM via SSH
- Use the following commands and answer Y when prompted
- sudo apt update
- sudo apt install snapd